
PostgreSQL supports array datatypes which can be indexed to allow fast searching by overlap and intersection, this makes them ideal for small to medium scale faceted search.
Faceted search is a common feature in web shops; you select a product category and the shop displays a list of attributes that the products in the category have. You then narrow down your search by selecting which properties the products must have, until you are left with a small subset of products that will hopefully contain the product you are looking for. From a database design there are several ways of doing this and each has it's own goods, bads and uglies.
One design that we are probably all familiar with is the Entity-Attribute-Value model:
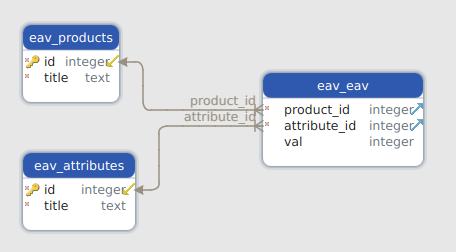
Products, attributes and a table connecting products to atributes and supplying a value for the attribute. To find which products have all the attributes you selected, you have to do a query on the eav_eav table for each attribute and it's desired value, and check if the number of matches is equal to the number of attributes you are searching for.
Let's hava go. The following will create the three tables and add products, attributes and link them in the eav_eav table. The actual data is nonsense but the principle holds.
- code
-
-- Cleanup. DROP TABLE IF EXISTS eav_eav; DROP TABLE IF EXISTS eav_attributes; DROP TABLE IF EXISTS eav_products; -- Create the tables and stuff them full of data. CREATE TABLE eav_products AS SELECT g::INT AS id, 'prod_' || g AS title FROM GENERATE_SERIES(1, 10000) AS g; ALTER TABLE eav_products ADD PRIMARY KEY (id); CREATE TABLE eav_attributes AS SELECT g::INT AS id, 'attr_' || g AS title FROM GENERATE_SERIES(1, 1000) AS g; ALTER TABLE eav_attributes ADD PRIMARY KEY (id); CREATE TABLE eav_eav AS SELECT eav_products.id AS product_id, eav_attributes.id AS attribute_id, eav_products.id % 10 AS val FROM eav_products, eav_attributes WHERE (eav_products.id + eav_attributes.id) % 1000 < (eav_products.id % 10);
A query to lookup particular products would look like:
- code
-
SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id = 992 and val = 8) OR (attribute_id = 993 and val = 8) OR (attribute_id = 994 and val = 8) OR (attribute_id = 995 and val = 8) OR (attribute_id = 996 and val = 8) OR (attribute_id = 997 and val = 8) OR (attribute_id = 998 and val = 8) OR (attribute_id = 999 and val = 8) GROUP BY product_id HAVING COUNT(*) = 8;
If you change the number of products and attributes you may find that this particular set nolonger exists in your database so here's a query that generates these queries based on actual data so you are guaranteed to find something (this is important for performance testing, a query that will not return anything can be extremely fast just because the planner could work this out because of an index)
- code
-
SELECT product_id, count(*), 'SELECT product_id, COUNT(*) FROM eav_eav WHERE ' || STRING_AGG('(attribute_id=' || attribute_id || ' and val=' || val || ')', ' OR ') || ' GROUP BY product_id HAVING COUNT(*) = ' || count(*) || ';' FROM eav_eav GROUP BY product_id; This will return something like: 1 1 "SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id=999 and val=1) GROUP BY product_id HAVING COUNT(*) = 1;" 2 2 "SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id=998 and val=2) OR (attribute_id=999 and val=2) GROUP BY product_id HAVING COUNT(*) = 2;" 3 3 "SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id=997 and val=3) OR (attribute_id=998 and val=3) OR (attribute_id=999 and val=3) GROUP BY product_id HAVING COUNT(*) = 3;" 4 4 "SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id=996 and val=4) OR (attribute_id=997 and val=4) OR (attribute_id=998 and val=4) OR (attribute_id=999 and val=4) GROUP BY product_id HAVING COUNT(*) = 4;" 5 5 "SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id=995 and val=5) OR (attribute_id=996 and val=5) OR (attribute_id=997 and val=5) OR (attribute_id=998 and val=5) OR (attribute_id=999 and val=5) GROUP BY product_id HAVING COUNT(*) = 5;" 6 6 "SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id=994 and val=6) OR (attribute_id=995 and val=6) OR (attribute_id=996 and val=6) OR (attribute_id=997 and val=6) OR (attribute_id=998 and val=6) OR (attribute_id=999 and val=6) GROUP BY product_id HAVING COUNT(*) = 6;"
Without any indexes the queryplan is not good, and neither is the performance.
- code
-
EXPLAIN ANALYSE SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id = 992 and val = 8) OR (attribute_id = 993 and val = 8) OR (attribute_id = 994 and val = 8) OR (attribute_id = 995 and val = 8) OR (attribute_id = 996 and val = 8) OR (attribute_id = 997 and val = 8) OR (attribute_id = 998 and val = 8) OR (attribute_id = 999 and val = 8) GROUP BY product_id HAVING COUNT(*) = 8; QUERY PLAN GroupAggregate (cost=1708.72..1710.34 rows=1 width=12) (actual time=3.635..3.645 rows=10 loops=1) Group Key: product_id Filter: (count(*) = 8) -> Sort (cost=1708.72..1708.90 rows=72 width=4) (actual time=3.627..3.631 rows=80 loops=1) Sort Key: product_id Sort Method: quicksort Memory: 28kB -> Seq Scan on eav_eav (cost=0.00..1706.50 rows=72 width=4) (actual time=0.016..3.612 rows=80 loops=1) Filter: ((val = 8) AND ((attribute_id = 992) OR (attribute_id = 993) OR (attribute_id = 994) OR (attribute_id = 995) OR (attribute_id = 996) OR (attribute_id = 997) OR (attribute_id = 998) OR (attribute_id = 999))) Rows Removed by Filter: 44920 Planning Time: 0.070 ms Execution Time: 3.671 ms
Notice how the series of OR statements takes up most of the time as the database plows through all records in eav_eav to find the ones that meet the OR's, and then has to aggregate the results to see if there are enough to satisfy the WHERE.
Adding an index helps a lot here:
- code
-
CREATE INDEX idx_eav_attr_val ON eav_eav(attribute_id, val); EXPLAIN ANALYSE SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id = 992 and val = 8) OR (attribute_id = 993 and val = 8) OR (attribute_id = 994 and val = 8) OR (attribute_id = 995 and val = 8) OR (attribute_id = 996 and val = 8) OR (attribute_id = 997 and val = 8) OR (attribute_id = 998 and val = 8) OR (attribute_id = 999 and val = 8) GROUP BY product_id HAVING COUNT(*) = 8; QUERY PLAN HashAggregate (cost=197.50..198.42 rows=1 width=12) (actual time=0.057..0.058 rows=10 loops=1) Group Key: product_id Filter: (count(*) = 8) -> Bitmap Heap Scan on eav_eav (cost=35.20..196.96 rows=73 width=4) (actual time=0.027..0.041 rows=80 loops=1) Recheck Cond: (((attribute_id = 992) AND (val = 8)) OR ((attribute_id = 993) AND (val = 8)) OR ((attribute_id = 994) AND (val = 8)) OR ((attribute_id = 995) AND (val = 8)) OR ((attribute_id = 996) AND (val = 8)) OR ((attribute_id = 997) AND (val = 8)) OR ((attribute_id = 998) AND (val = 8)) OR ((attribute_id = 999) AND (val = 8))) Heap Blocks: exact=10 -> BitmapOr (cost=35.20..35.20 rows=74 width=0) (actual time=0.022..0.022 rows=0 loops=1) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..4.37 rows=8 width=0) (actual time=0.010..0.010 rows=10 loops=1) Index Cond: ((attribute_id = 992) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..4.37 rows=8 width=0) (actual time=0.002..0.002 rows=10 loops=1) Index Cond: ((attribute_id = 993) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..4.37 rows=8 width=0) (actual time=0.001..0.001 rows=10 loops=1) Index Cond: ((attribute_id = 994) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..4.37 rows=8 width=0) (actual time=0.002..0.002 rows=10 loops=1) Index Cond: ((attribute_id = 995) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..4.37 rows=8 width=0) (actual time=0.001..0.001 rows=10 loops=1) Index Cond: ((attribute_id = 996) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..4.37 rows=8 width=0) (actual time=0.001..0.001 rows=10 loops=1) Index Cond: ((attribute_id = 997) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..4.37 rows=8 width=0) (actual time=0.001..0.001 rows=10 loops=1) Index Cond: ((attribute_id = 998) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..4.46 rows=17 width=0) (actual time=0.001..0.001 rows=10 loops=1) Index Cond: ((attribute_id = 999) AND (val = 8)) Planning Time: 0.127 ms Execution Time: 0.098 ms
That has reduced the execution time from ~3.5ms to ~0.1ms, but the planner now spends 0.127ms thinking about how to deal with this query, this is ten times as much as for the sequential scan.
Before we look at how array's perform, lets see how much diskspace this design is using up.
Note: This query uses pg_size_pretty(), which uses proper kilobytes=1024 bytes, and one Megabyte = 1024 KiloBytes = 1048576 Bytes. You *will* see the sum not adding up, but it actually is.
- code
-
SELECT coalesce(relname, 'Total') AS "relation", pg_size_pretty(SUM(pg_relation_size(oid))) AS "size in kB" FROM pg_class WHERE relname IN ('eav_products', 'eav_attributes', 'eav_eav', 'idx_eav_product_attributes', 'idx_eav_attr_val') GROUP BY ROLLUP ((relname)) ORDER BY relname; relation size in kB eav_attributes 48 kB eav_eav 1952 kB eav_products 440 kB idx_eav_attr_val 1000 kB Total 3440 kB
Now for the arrays.
First modify the products table to add an attributes column, then fill that column with an array of strings that represent the attribute-value pairs from the eav_eav table.
- code
-
ALTER TABLE eav_products ADD COLUMN attributes TEXT[]; WITH attrs AS (SELECT product_id, ARRAY_AGG(eav_eav.attribute_id || ':' || eav_eav.val) AS a FROM eav_products INNER JOIN eav_eav ON eav_products.id = eav_eav.product_id GROUP BY product_id ) UPDATE eav_products SET attributes = attrs.a FROM attrs WHERE attrs.product_id = eav_products.id;
The query for getting records wil ofcourse also change, so here's another query to generate the queries:
- code
-
SELECT id, COUNT(*), 'SELECT * FROM eav_products WHERE attributes @> ARRAY[' || STRING_AGG(quote_literal(a), ',') || '];' AS query FROM eav_products, unnest(attributes) AS a GROUP BY id; id count query ------------------------- 1 1 SELECT * FROM eav_products WHERE attributes @> ARRAY['999:1']; 2 2 SELECT * FROM eav_products WHERE attributes @> ARRAY['998:2','999:2']; 3 3 SELECT * FROM eav_products WHERE attributes @> ARRAY['997:3','998:3','999:3'];
And how is the performance without indexes?
- code
-
EXPLAIN ANALYSE SELECT id, title FROM eav_products WHERE attributes @> ARRAY['992:8','993:8','994:8','995:8','996:8','997:8','998:8','999:8']; QUERY PLAN Seq Scan on eav_products (cost=0.00..318.00 rows=1 width=13) (actual time=0.124..2.734 rows=10 loops=1) Filter: (attributes @> '{992:8,993:8,994:8,995:8,996:8,997:8,998:8,999:8}'::text[]) Rows Removed by Filter: 9990 Planning Time: 0.077 ms Execution Time: 2.747 ms
That's ~2.8ms. It's already faster while doing a sequential scan, so lets add an index. PostgreSQL can index arrays using GIN:
- code
-
CREATE INDEX idx_eav_product_attributes ON eav_products USING GIN(attributes); EXPLAIN ANALYSE SELECT id, title FROM eav_products WHERE attributes @> ARRAY['992:8','993:8','994:8','995:8','996:8','997:8','998:8','999:8']; QUERY PLAN Bitmap Heap Scan on eav_products (cost=68.00..72.01 rows=1 width=13) (actual time=0.027..0.036 rows=10 loops=1) Recheck Cond: (attributes @> '{992:8,993:8,994:8,995:8,996:8,997:8,998:8,999:8}'::text[]) Heap Blocks: exact=10 -> Bitmap Index Scan on idx_eav_product_attributes (cost=0.00..68.00 rows=1 width=0) (actual time=0.022..0.022 rows=10 loops=1) Index Cond: (attributes @> '{992:8,993:8,994:8,995:8,996:8,997:8,998:8,999:8}'::text[]) Planning Time: 0.088 ms Execution Time: 0.063 ms
Planning time is down to ~0.09ms and execution time is ~0.06ms
How much space does all of this take up now? Ofcourse we got rid of the eav_eav table and its index, but we added a large column to the eav_product table and indexed it using a fancy indexing algorithm.
- code
-
SELECT coalesce(relname, 'Total') AS "relation", pg_size_pretty(SUM(pg_relation_size(oid))) AS "size in kB" FROM pg_class WHERE relname IN ('eav_products', 'eav_attributes', 'eav_eav', 'idx_eav_product_attributes', 'idx_eav_attr_val') GROUP BY ROLLUP ((relname)) ORDER BY relname; relation size in kB eav_attributes 48 kB eav_products 1544 kB idx_eav_product_attributes 536 kB Total 2128 kB
That's 1300kB less.
So does it scale? What if there are 1M products? Just increase the 10000 in the generate_series to 1000000 and wait a few minutes, depending on how fast your machine is.
Using the same queries the results are
- code
-
DROP TABLE IF EXISTS eav_eav; DROP TABLE IF EXISTS eav_attributes; DROP TABLE IF EXISTS eav_products; CREATE TABLE eav_products AS SELECT g::INT AS id, 'prod_' || g AS title FROM GENERATE_SERIES(1, 1000000) AS g; ALTER TABLE eav_products ADD PRIMARY KEY (id); CREATE TABLE eav_attributes AS SELECT g::INT AS id, 'attr_' || g AS title FROM GENERATE_SERIES(1, 1000) AS g; ALTER TABLE eav_attributes ADD PRIMARY KEY (id); CREATE TABLE eav_eav AS SELECT eav_products.id AS product_id, eav_attributes.id AS attribute_id, eav_products.id % 10 AS val FROM eav_products, eav_attributes WHERE (eav_products.id + eav_attributes.id) % 1000 < (eav_products.id % 10); EXPLAIN ANALYSE SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id = 992 and val = 8) OR (attribute_id = 993 and val = 8) OR (attribute_id = 994 and val = 8) OR (attribute_id = 995 and val = 8) OR (attribute_id = 996 and val = 8) OR (attribute_id = 997 and val = 8) OR (attribute_id = 998 and val = 8) OR (attribute_id = 999 and val = 8) GROUP BY product_id HAVING COUNT(*) = 8; QUERY PLAN Finalize GroupAggregate (cost=86433.19..87301.10 rows=35 width=12) (actual time=151.333..152.099 rows=1000 loops=1) Group Key: product_id Filter: (count(*) = 8) -> Gather Merge (cost=86433.19..87168.30 rows=5920 width=12) (actual time=151.322..154.380 rows=1052 loops=1) Workers Planned: 2 Workers Launched: 2 -> Partial GroupAggregate (cost=85433.16..85484.96 rows=2960 width=12) (actual time=134.381..134.768 rows=351 loops=3) Group Key: product_id -> Sort (cost=85433.16..85440.56 rows=2960 width=4) (actual time=134.374..134.492 rows=2667 loops=3) Sort Key: product_id Sort Method: quicksort Memory: 216kB Worker 0: Sort Method: quicksort Memory: 223kB Worker 1: Sort Method: quicksort Memory: 225kB -> Parallel Seq Scan on eav_eav (cost=0.00..85262.50 rows=2960 width=4) (actual time=0.119..133.891 rows=2667 loops=3) Filter: ((val = 8) AND ((attribute_id = 992) OR (attribute_id = 993) OR (attribute_id = 994) OR (attribute_id = 995) OR (attribute_id = 996) OR (attribute_id = 997) OR (attribute_id = 998) OR (attribute_id = 999))) Rows Removed by Filter: 1497333 Planning Time: 0.126 ms Execution Time: 154.686 ms CREATE INDEX idx_eav_attr_val ON eav_eav(attribute_id, val); EXPLAIN ANALYSE SELECT product_id, COUNT(*) FROM eav_eav WHERE (attribute_id = 992 and val = 8) OR (attribute_id = 993 and val = 8) OR (attribute_id = 994 and val = 8) OR (attribute_id = 995 and val = 8) OR (attribute_id = 996 and val = 8) OR (attribute_id = 997 and val = 8) OR (attribute_id = 998 and val = 8) OR (attribute_id = 999 and val = 8) GROUP BY product_id HAVING COUNT(*) = 8; QUERY PLAN HashAggregate (cost=15920.41..16008.81 rows=35 width=12) (actual time=3.465..3.616 rows=1000 loops=1) Group Key: product_id Filter: (count(*) = 8) -> Bitmap Heap Scan on eav_eav (cost=192.98..15867.14 rows=7103 width=4) (actual time=0.643..2.246 rows=8000 loops=1) Recheck Cond: (((attribute_id = 992) AND (val = 8)) OR ((attribute_id = 993) AND (val = 8)) OR ((attribute_id = 994) AND (val = 8)) OR ((attribute_id = 995) AND (val = 8)) OR ((attribute_id = 996) AND (val = 8)) OR ((attribute_id = 997) AND (val = 8)) OR ((attribute_id = 998) AND (val = 8)) OR ((attribute_id = 999) AND (val = 8))) Heap Blocks: exact=1054 -> BitmapOr (cost=192.98..192.98 rows=7130 width=0) (actual time=0.537..0.538 rows=0 loops=1) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..20.21 rows=778 width=0) (actual time=0.170..0.170 rows=1000 loops=1) Index Cond: ((attribute_id = 992) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..20.21 rows=778 width=0) (actual time=0.075..0.075 rows=1000 loops=1) Index Cond: ((attribute_id = 993) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..20.21 rows=778 width=0) (actual time=0.082..0.082 rows=1000 loops=1) Index Cond: ((attribute_id = 994) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..20.21 rows=778 width=0) (actual time=0.053..0.053 rows=1000 loops=1) Index Cond: ((attribute_id = 995) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..20.21 rows=778 width=0) (actual time=0.039..0.039 rows=1000 loops=1) Index Cond: ((attribute_id = 996) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..20.21 rows=778 width=0) (actual time=0.039..0.039 rows=1000 loops=1) Index Cond: ((attribute_id = 997) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..37.28 rows=1685 width=0) (actual time=0.038..0.038 rows=1000 loops=1) Index Cond: ((attribute_id = 998) AND (val = 8)) -> Bitmap Index Scan on idx_eav_attr_val (cost=0.00..20.21 rows=778 width=0) (actual time=0.040..0.040 rows=1000 loops=1) Index Cond: ((attribute_id = 999) AND (val = 8)) Planning Time: 0.118 ms Execution Time: 3.742 ms SELECT coalesce(relname, 'Total') AS "relation", pg_size_pretty(SUM(pg_relation_size(oid))) AS "size" FROM pg_class WHERE relname IN ('eav_products', 'eav_attributes', 'eav_eav', 'idx_eav_product_attributes', 'idx_eav_attr_val') GROUP BY ROLLUP ((relname)) ORDER BY relname; relation size eav_attributes 48 kB eav_eav 190 MB eav_products 42 MB idx_eav_attr_val 97 MB Total 329 MB ALTER TABLE eav_products ADD COLUMN attributes TEXT[]; WITH attrs AS (SELECT product_id, ARRAY_AGG(eav_eav.attribute_id || ':' || eav_eav.val) AS a FROM eav_products INNER JOIN eav_eav ON eav_products.id = eav_eav.product_id GROUP BY product_id ) UPDATE eav_products SET attributes = attrs.a FROM attrs WHERE attrs.product_id = eav_products.id; QUERY PLAN Gather (cost=1000.00..39422.57 rows=1 width=15) (actual time=16.744..115.603 rows=1000 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on eav_products (cost=0.00..38422.47 rows=1 width=15) (actual time=6.822..101.955 rows=333 loops=3) Filter: (attributes @> '{992:8,993:8,994:8,995:8,996:8,997:8,998:8,999:8}'::text[]) Rows Removed by Filter: 333000 Planning Time: 0.068 ms Execution Time: 115.667 ms CREATE INDEX idx_eav_product_attributes ON eav_products USING GIN(attributes); EXPLAIN ANALYSE SELECT id, title FROM eav_products WHERE attributes @> ARRAY['992:8','993:8','994:8','995:8','996:8','997:8','998:8','999:8']; QUERY PLAN Bitmap Heap Scan on eav_products (cost=100.00..104.01 rows=1 width=15) (actual time=0.505..1.301 rows=1000 loops=1) Recheck Cond: (attributes @> '{992:8,993:8,994:8,995:8,996:8,997:8,998:8,999:8}'::text[]) Heap Blocks: exact=1000 -> Bitmap Index Scan on idx_eav_product_attributes (cost=0.00..100.00 rows=1 width=0) (actual time=0.395..0.395 rows=1000 loops=1) Index Cond: (attributes @> '{992:8,993:8,994:8,995:8,996:8,997:8,998:8,999:8}'::text[]) Planning Time: 0.055 ms Execution Time: 1.349 ms SELECT coalesce(relname, 'Total') AS "relation", pg_size_pretty(SUM(pg_relation_size(oid))) AS "size" FROM pg_class WHERE relname IN ('eav_products', 'eav_attributes', 'eav_eav', 'idx_eav_product_attributes', 'idx_eav_attr_val') GROUP BY ROLLUP ((relname)) ORDER BY relname; relation size eav_attributes 48 kB eav_products 153 MB idx_eav_product_attributes 35 MB Total 188 MB
Both methods scale remarkably well, but the array method is always much faster.
caveats.
Obviously the performance measurements I did are *way* too simple and do not represent a realistic workload. Your mileage may vary.
Yes I know that the time the EAV takes is quote short too, the point is that arrays are an order of magnitude faster. Anything that takes longer will generally cause more problems and create them sooner, at lower workloads.
There is no referential integrity built in; you can remove an attribute from eav_attributes and it will still be referenced in the eav_products table. If this is a problem in your setup then you can build an extremely simple trigger to clean the attributes table. No, triggers are not evil or slow, they are lovely and keep you from writing the exact same functionality in your app.